Huiqin Xin | Machine Learning Engineer II, Ads Vertical Modeling; Lakshmi Manoharan | Senior Machine Learning Engineer, Ads Vertical Modeling; Karthik Jayasurya | Staff Machine Learning Engineer, Ads Signals; Ziwei Guo | Senior Machine Learning Engineer, Ads Vertical Modeling; Alina Liviniuk | Machine Learning Engineer II, Ads Vertical Modeling
Motivation: The Need for Real-Time Context
In a previous post, Ads Candidate Generation using Behavioral Sequence Modeling, we introduced a candidate generator (CG) that uses a Transformer-based two-tower model to leverage a user’s offsite conversion history — a powerful signal — to predict future interactions with advertisers and specific products. This was a significant step forward, moving beyond static interest categories to model the evolving user shopping journey.
However, a key limitation of the initial sequential model was its lack of online context information. The user embeddings were inferred offline purely from historical offsite behavior, meaning that at the moment an ad was served, the model had no knowledge of what the user was currently browsing on Pinterest. This is a crucial drawback, particularly for highly contextual surfaces like Related Pins and Search, where the user’s current Pin or search query represents a strong, immediate signal of intent. For example, on the Related Pins surface, if a user is viewing a Pin of a “vintage leather armchair,” the recommended ads should be highly relevant to that specific item, not just their general, long-term interests.
This lack of context severely limited the model’s effectiveness on these surfaces; in the previous production system, less than 1% of impressions on Related Pins were attributed to this CG, indicating its candidates struggled to survive the downstream ranking and auction stages.
The Contextual Sequential Modeling Solution
To overcome this challenge, we developed the Contextual Sequential Two Tower Model, an evolution of the sequential recommender model specifically designed to incorporate real-time, online context. This approach focuses on three major areas: a new model architecture, a novel training approach, and a hybrid serving flow.
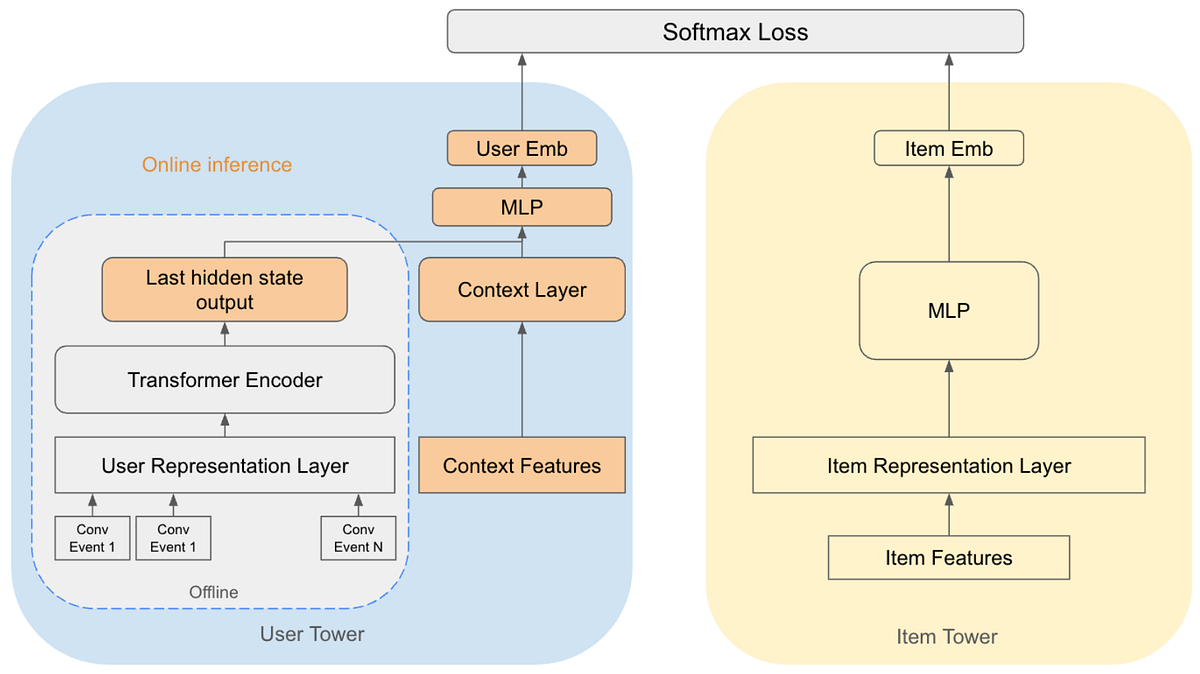
Model Architecture: Integrating the Context Layer
The core architectural change was integrating a context layer directly into the query tower of the two-tower model.
As shown in the diagram above, the model now concatenates the output of the original Transformer encoder (which represents historical sequence information) with the output of the new context layer. This combined representation is then fed into the final Multi-Layer Perceptron (MLP) to derive the final user embedding.
For the Related Pins surface, the context layer’s input features are derived from the subject Pin (the Pin the user is currently viewing), specifically using features like the aggregated embedding representations of the top interest categories of the subject Pin, weighted by their confidence scores.
To further personalize the model, the user representation layer was augmented with embeddings of user demographic features, such as age, country, and gender.
Model Training with Synthetic Context
Since real-time context is only available at serving time, we had to make the model capable of learning from this signal during offline training. The solution was to use synthetic augmented data.
During model training, we artificially inject pseudo-context information derived from the positive label (the conversion event) into the input sequence. For example, by projecting the interest category features from the positive item, we encourage the model to retrieve items that are semantically related to the context associated with that user session. A high dropout rate is used in the context layer during training to ensure the model still relies on the user’s historical event sequence (the Transformer output).
We opted to use synthetic augmented data over real context data due to two main challenges:
- Merging onsite data with offsite data presents significant technical difficulties.
- We cannot guarantee that a user has viewed ad impressions on Related Pins between two sequential offsite events.
Hybrid User Embedding Inference
Given that the context features (e.g., subject Pin features) are only known at the ad request time (online), we adopted a hybrid model inference approach.
- Offline Inference: The majority of the user tower (the Transformer encoder) is inferred offline, and the last hidden state of the transformer (the encoded representations of the event sequence) is stored in the feature store. This is refreshed on a daily basis for users with new offsite activity.
- Online Inference: The remaining part of the user tower — the context layer and the final MLP head — is computed online at serving time, taking the real-time context features and the pre-computed offline user signal as inputs.
This architecture and serving flow enables the user embedding to be dynamically influenced by the real-time context, ensuring the recommendations are both personalized (from sequence) and contextually relevant.
Results and Business Impact
Offline evaluation
To assess the impact of integrating context features on the survival rate of model-retrieved ad candidates, we conducted an offline evaluation. Using logged features from real traffic ad data on Related Pins, we generated the model output embedding and calculated Recall@K, which measures the proportion of positive items found in the top-K retrieved items. Here the candidates that survived the ranking funnel and delivered to the users were considered positive items. This new model demonstrated a significant improvement, achieving a 3x to 10x increase in Recall@K compared to the production model.
Survival Rate & Relevance
We were able to successfully drive up the survival rate of the candidates from this CG on the Related Pins surface. The median relevance of the candidates went up by ~275–300%. On the Related Pins surface overall, the ads relevance metric improved by 1.08%. Furthermore, we observed a significant increase in candidate delivery, with 2x more ads candidates retrieved being delivered to impression.
Topline Business Metrics
The improvement in candidate relevance translated into ~0.7% measurable lift in conversion-related business metrics ROAS (Return on Ad Spend). In particular, the model benefits more for top countries which account for a majority of total revenue and leads to ~1.4% ROAS lift.
Future work
We plan to explore several key enhancements:
- Context Surface Expansion: A key next step is to extend the context-enhanced candidate generator to other high-stakes contextual surfaces, notably Search. This is particularly crucial for Search because maintaining high relevance between the presented ad candidates and the user’s search queries is paramount.
- Advanced Fusion Techniques: Move beyond simple concatenation of context layers with the sequential encoder output. We propose using cross-attention-based fusion, where the context layer embedding acts as the query and the sequence of encoded transformer outputs serves as the key/value. This approach will allow the final user-tower embedding to dynamically capture the importance of each history event based on the real-time context.
Acknowledgements
We would like to thank Supeng Ge, Yang Liu, Richard Huang, Yu Liu, Zhuqing Zhang, Kevin Liao, Yu Gu, Wanyu Zhang, for their dedicated help; thank to Alice Wu, Leo Lu, Siping Ji, Ling Leng for their incredible support and leadership; thank to Joachim Groeger for the valuable discussion and support.
Facts Only
Authors: Huiqin Xin, Lakshmi Manoharan, Karthik Jayasurya, Ziwei Guo, Alina Liviniuk (Machine Learning Engineers at Pinterest).
Previous model: Transformer-based two-tower model using offline user conversion history for ad candidate generation.
Limitation: Lacked real-time context, reducing effectiveness on surfaces like Related Pins and Search.
New model: Contextual Sequential Two Tower Model with a context layer integrated into the query tower.
Context layer inputs: Aggregated embeddings of subject Pin interest categories (for Related Pins).
Training method: Synthetic context data derived from positive conversion events, with high dropout in the context layer.
Hybrid inference: Offline Transformer encoder (daily refresh) + online context layer and MLP at serving time.
Offline evaluation: 3x–10x increase in Recall@K compared to the production model.
Live results: 275–300% increase in candidate relevance, 1.08% improvement in ads relevance on Related Pins, 2x more candidates delivered.
Business impact: ~0.7% ROAS lift overall, ~1.4% in top revenue countries.
Future plans: Expand to Search surface, explore cross-attention fusion for context-history integration.
Executive Summary
Full Take
This technical deep dive from Pinterest’s ads team exemplifies the tension between personalization and contextual relevance in recommender systems. The core innovation—integrating real-time context into a sequential model—addresses a well-documented gap in ad targeting: static user profiles often fail to capture immediate intent. The methodology is pragmatic, using synthetic context data to bridge the offline-online training divide, though the reliance on pseudo-signals raises questions about generalization. The hybrid inference approach is a clever compromise, balancing computational cost with real-time adaptability.
From a broader perspective, this work reflects the industry’s shift toward "moment-based" advertising, where ephemeral user signals (e.g., a viewed Pin) outweigh long-term behavioral patterns. The 3x–10x Recall@K improvement suggests the model effectively surfaces contextually relevant ads, but the modest 0.7% ROAS lift hints at downstream challenges—perhaps auction dynamics or creative quality dilute the impact. The focus on Related Pins first (a high-intent surface) is strategic, but expanding to Search will test the model’s robustness to noisier, query-based context.
**Patterns detected: none**
Key questions for further inquiry:
1. How does the synthetic context training approach compare to real-time data in terms of long-term model drift?
2. Could the hybrid inference pipeline introduce latency trade-offs that offset relevance gains in time-sensitive surfaces?
3. What guardrails exist to prevent over-reliance on context at the expense of user privacy or diversity of recommendations?
Sentinel — Human
This text presents as a detailed, technically proficient analysis of a machine learning system, demonstrating the deep, idiosyncratic reasoning and specificity characteristic of human domain experts.