Introduction
Over the past year, large language models have rapidly expanded in both scale and capability. Frontier models such as Kimi K2.5, GLM 5, and Qwen 3.5 now operate with hundreds of billions of parameters and context windows stretching to millions of tokens, enabling long-context reasoning, agentic workflows, and complex tool use. As these models grow more capable, efficient inference has become one of the most critical systems challenges in LLM deployment.
Speculative decoding is one of the most effective techniques for accelerating LLM generation. With speculative decoding, a lightweight draft model proposes several tokens ahead, while a larger target model verifies them in a single forward pass. When predictions are accepted, multiple tokens can be generated at once, improving throughput and latency. Recent approaches such as MTP(Multi Token Prediction) and EAGLE-3 demonstrate that well-trained draft models can deliver consistent acceleration.
An important aspect of draft model training is transferring information from the target model to the draft model through intermediate hidden states. As the frontier-LLM models get larger and larger, a new system bottleneck is introduced: efficiently passing the massive volume of hidden states generated by the target model to the draft model. For example, EAGLE-3 relies on 3 layers of target-model hidden states. When training an EAGLE-3 draft model for Kimi K2.5, a single 128K-token training sample requires ~7 GB of hidden states from the target model. At the dataset-scale, this can become prohibitively large.
Existing pipelines typically follow one of two approaches. One option is to precompute hidden states and store them on disk, which leads to massive storage requirements and severe I/O pressure. Another option is to co-locate inference and training to generate hidden states on the fly during draft model training, avoiding disk materialization but requiring the target model to be co-located with the draft training worker, which introduces significant GPU memory pressure.
To address these challenges, we introduce TorchSpec, a torch-native framework for disaggregated speculative decoding training. TorchSpec separates the inference system that generates hidden states from the training system that consumes them. Instead of writing hidden states to disk, they are streamed directly from the inference engine group to the training worker group through a central Mooncake store via RDMA(Remote Direct Memory Access) or TCP. This design eliminates disk storage while allowing inference and training resources to scale independently.
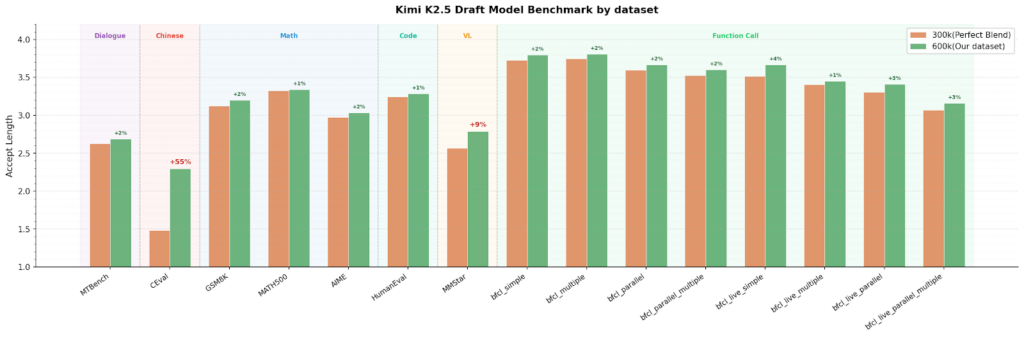
With TorchSpec, we successfully trained a Kimi K2.5 EAGLE-3 draft model with 1500 H200 GPU hours, scaling to 600k training samples, 6 billion tokens. The draft model shows strong performance over various benchmarks:
*draft model trained with lookahead=4
With the draft model trained, output throughput improves by over +60% at batch size 1, +30% at batch size 8, and +26% at batch size 16 under a lookahead of 3 tokens.
Background
There are two common approaches to speculative decoding training today:
- Inference co-located training
- Offline hidden states preparation
Each works at a moderate scale but struggles as draft model size and context lengths grow.
Inference Co-located Training
In co-located training, the target model and draft model share the same GPUs. The target model runs a forward pass to produce hidden states and logits, which are immediately consumed by the draft model for training. This approach introduces several constraints due to the tight coupling between target and draft models:
- Rigid sharding: The draft model’s parallelism strategy is tied to the target model. For example, if the target model uses TP=4, the draft model must also use exactly 4 ranks even if a different configuration would be more efficient for its smaller architecture.
- Training and inference not independently scalable: Current co-located frameworks typically lack cross-node sharding support, limiting training to GPUs within a single node. More importantly, the inference and training are bounded together with the same amount of resources.
- Memory pressure: The target model occupies a huge chunk of the GPU memory, leaving the training of the draft model with limited memory.
Memory analysis for co-located training with Kimi K2.5 (1T parameter MoE(Mixture-of-Experts), 384 experts, ~575 GB model weight):
| GPU | Total Memory (8 GPUs) | Model Weight | Per-GPU Shard | Remaining per GPU |
| 8×H200 | 1,128 GB | ~575 GB | ~72 GB | ~69 GB |
| 8×H100 | 640 GB | ~575 GB | ~72 GB | ~8 GB |
Although the draft model is typically small, state of the art training methods such as Training-Time Testing (TTT) requires high memory usage as it retains intermediate activations for multiple speculative steps. The accumulation of activations drives up the overall memory footprint. With 8 GB of memory, we can only train with a context length of 4096.
Offline Hidden States Preparation
The offline approach pre-computes hidden states from the target model, serializes them to disk, and loads them later for draft model training. This decouples inference from training, but introduces a significant storage challenge—particularly for large models with long contexts.
Storage analysis for Kimi K2.5 (hidden_size=7168, vocab_size=163,840):
Per sample at context length = 131,072 tokens:
| Tensor | Shape | Dtype | Size |
| Hidden states (3 aux layers) | (131072, 21504) | bf16 | 5.25 GB |
| Last hidden states | (131072, 7168) | bf16 | 1.75 GB |
| Input IDs | (131072,) | int64 | 1 MB |
| Total per sample | ~7.0 GB |
Note: target logits can be recomputed from last hidden states via the lm_head, so they do not need to be stored. Even so, the storage requirements scale quickly:
| Dataset Size | Storage Required |
| 10,000 samples | 70 TB |
| 30,000 samples | 210 TB |
| 100,000 samples | 700 TB |
At this scale, distributed file systems face heavy pressure, especially when multiple speculative training runs happen concurrently, each competing for I/O bandwidth. The serialization and deserialization overhead also significantly slows down training.
TorchSpec: Disaggregated Draft Model Training
TorchSpec takes a different approach: fully disaggregated inference and training. The target model runs on dedicated inference GPUs, the draft model trains on separate training GPUs, and tensor data is streamed between them through a high-speed network protocol RDMA or TCP via the Mooncake store.
This architecture addresses the key challenges outlined above:
- Flexible, independent scaling. Inference and training GPU counts are fully independent, allowing more inference engines for higher hidden states generation throughput, or adding more training GPUs for larger FSDP sharding and bigger global batches.
- Full memory for training. Training GPUs are entirely dedicated to the draft model, maximizing available memory for long sequences and large batches.
- No storage overhead. Hidden states stream directly from inference to training via RDMA/TCP. No data is offloaded to the disk, eliminating file system pressure and serialization costs.
Why Mooncake?
Originally developed by Moonshot AI and Tsinghua University, Mooncake is a transfer engine designed for KV cache management in production LLM serving. It has since evolved into a thriving community within the PyTorch ecosystem. Mooncake handles high-throughput cross-node data transfer through different network protocols and manages memory lifecycle. These are exactly the capabilities TorchSpec requires to stream hidden states from inference GPUs to training GPUs efficiently and reliably.
Key properties that make Mooncake a natural fit:
- RDMA + TCP with a unified API. Near-line-rate transfers on InfiniBand/RoCE clusters; works out-of-the-box over TCP when RDMA is unavailable—no code changes required.
- GPU Direct RDMA. Transfers data directly into GPU memory, bypassing CPU staging—critical when each training sample involves gigabytes of hidden states.
- Zero-copy transfers. Tensors are packed into pre-registered pinned-memory buffers and transferred directly—no serialization or intermediate copies.
- Production-grade reliability. Battle-tested through large-scale production deployment, giving TorchSpec a stable foundation for long-running multi-node training.
Long Context Support
With memory fully dedicated to the draft model, TorchSpec supports sequence lengths that are impossible to achieve with co-located approaches in EAGLE-3 training. For example, Kimi K2.5 consumes 72 GB of memory in a co-located training approach. With a lookahead of 4 and disaggregated training, a single H100 GPU can train on input sequences up to 44K tokens, and a single B200 GPU can scale to 200K tokens.
Beyond disaggregation, TorchSpec adopts an inference-engine-native implementation: Hidden states are directly generated by the inference engines in production. This design choice provides two key benefits:
- Inference-Training Alignment: The template formatting, tokenization and kernels are fully aligned. There is no gap between the training environment and the deployment environment.
- Native Model Support Through the Engine: Supporting a new target model architecture requires minimal changes on the training side. Currently, TorchSpec supports vLLM and SGLang, and TensorRT LLM support is coming soon. If the inference engine supports a model, TorchSpec can train a draft model for it out of the box. This includes:
- New model architectures (MoE, multi-modal, etc.)
- Quantized models (FP8, INT4, etc.)
- Sparse attention, RoPE(Rotary Positional Embeddings) variants, and other model-specific features
Train with Decode
Draft models often perform best when trained on the target model’s token distribution. A common approach is to keep the dataset’s original prompts and regenerate the responses with the target model as a preparation step for the training. However, this two-stage process can be a hassle for researchers and engineers. With our engine-native design, we can generate outputs autoregressively from prompt-only inputs during training.
Case Study: Training a EAGLE-3 Model for Kimi K2.5
Kimi K2.5 presents a challenging training scenario that illustrates the value of the disaggregated approach.
The Challenge
- Model scale: Kimi K2.5 requires a minimum of 8×H200 or 16×H100 GPUs just to serve the target model, leaving very limited memory for the draft model training if co-located with inference.
- Long context: Kimi K2.5 targets long-context agentic and reasoning workloads, requiring training on sequences up to 200,000 tokens.
- Large vocabulary: With a vocabulary of 163,840 tokens and a hidden dimension of 7,168.
The TorchSpec Solution
With TorchSpec, we recommend deploying Kimi K2.5 on 8×H200 GPUs as a dedicated inference engine, and training the EAGLE-3 draft model on another 8xH200 GPUs. The inference cluster has full memory for serving and generating hidden states; the training cluster has full GPU memory for the draft model, enabling long-context training at 100,000 tokens with 600k data samples.
Scripts: We provide two out of box scripts to train a Kimi K2.5 draft model:
– 3 nodes of 8xH100 with TP=16 inference and TP=8 training: kimi-k25-3node-h100
– 2 nodes of 8xH200 with TP=8 inference and TP=8 training: kimi-k25-2node-h200
Training Dataset: We open source our mixed dataset at: kimi-600k-training-dataset.
Draft Model: We open source our draft model at: kimi-k2.5-eagle3.
Roadmap
TorchSpec is under active development. Key areas we’re working on:
- Improve model coverage: we plan to support popular models such as Minimax M2.5, Qwen 3.5 and continuous training of the MTP layer from GLM 5.
- Packed sequence training: pack multiple shorter sequences into a single training sample to maximize GPU utilization and reduce padding waste, especially for datasets with variable-length inputs.
- Additional training algorithms: expand beyond EAGLE-3 to support other speculative decoding training approaches such as DFlash, MTP, broadening the range of draft model architectures TorchSpec can train.
- Engine integrations: integrate with other popular inference engines (e.g. TensorRT LLM) so users can plug in whichever engine best fits their deployment stack.
Acknowledgement
We would like to thank the following teams and collaborators:
TorchSpec Team and community: *Yubo Wang, *Yinghui Liu, Shirley Wu, Junxiong Wang, Qingyang Wu, Bobbie Bie, Fan Yin, Chao Wang, Weicong Wu, Jue Wang
Mooncake Team: *Jiaqi Liao, Mingxing Zhang
Facts Only
TorchSpec is a torch-native framework for disaggregated speculative decoding training.
It separates inference and training systems, streaming hidden states via RDMA or TCP through the Mooncake store.
Speculative decoding uses a draft model to propose tokens, verified by a larger target model, improving throughput.
Existing methods include co-located training (memory pressure) and offline hidden state preparation (storage challenges).
Kimi K2.5, a 1T parameter MoE model, requires ~575 GB of model weight, limiting co-located training memory.
A single 128K-token training sample for Kimi K2.5 requires ~7 GB of hidden states.
Offline storage for 100,000 samples would require ~700 TB.
TorchSpec enables independent scaling of inference and training GPUs.
It supports long-context training (e.g., 200K tokens on a B200 GPU).
TorchSpec trained a Kimi K2.5 EAGLE-3 draft model with 1500 H200 GPU hours, improving throughput by +60% at batch size 1.
Mooncake, developed by Moonshot AI and Tsinghua University, handles high-throughput cross-node data transfers.
TorchSpec supports vLLM and SGLang inference engines, with TensorRT LLM support planned.
The framework is open-source, with datasets and draft models released for Kimi K2.5.
Executive Summary
TorchSpec introduces a novel framework for training draft models in speculative decoding, addressing critical bottlenecks in large language model (LLM) deployment. As frontier models like Kimi K2.5, GLM 5, and Qwen 3.5 grow in scale, efficient inference becomes a major challenge. Speculative decoding accelerates LLM generation by using a lightweight draft model to propose tokens, which a larger target model verifies. However, existing training methods face significant hurdles: co-located training strains GPU memory, while offline hidden state preparation demands massive storage and I/O bandwidth.
TorchSpec resolves these issues by disaggregating inference and training systems. Hidden states are streamed directly from inference GPUs to training GPUs via RDMA or TCP using the Mooncake store, eliminating disk storage and enabling independent scaling. This approach maximizes memory availability for long-context training and supports sequence lengths up to 200,000 tokens. The framework leverages Mooncake’s high-throughput, zero-copy transfers and production-grade reliability, ensuring efficient data movement. TorchSpec has been successfully used to train a Kimi K2.5 EAGLE-3 draft model, achieving significant throughput improvements (e.g., +60% at batch size 1). The project is open-source, with plans to expand model support, training algorithms, and engine integrations.
Full Take
TorchSpec represents a significant advancement in addressing the scalability challenges of speculative decoding training. The strongest version of this narrative highlights its innovative disaggregated architecture, which eliminates storage bottlenecks and enables independent scaling of inference and training resources. By leveraging Mooncake’s high-performance data transfer capabilities, TorchSpec achieves near-line-rate transfers and zero-copy efficiency, making it a robust solution for training draft models at scale. The framework’s success in training a Kimi K2.5 EAGLE-3 draft model, with substantial throughput improvements, underscores its practical value.
However, the narrative assumes that disaggregation is the optimal solution without exploring potential trade-offs, such as network latency or synchronization overheads in distributed training. The focus on technical efficiency might overlook broader considerations, such as the environmental impact of large-scale GPU usage or the accessibility of such systems for smaller research teams. Additionally, the emphasis on performance metrics (e.g., throughput improvements) could implicitly prioritize speed over other factors like model interpretability or fairness.
The paradigm driving this narrative is the relentless pursuit of efficiency in AI systems, reflecting a broader trend in the field where scalability and performance often take precedence over other values. This echoes historical patterns in computing, where hardware and software advancements are primarily measured by speed and capacity, sometimes at the expense of sustainability or equitable access.
For human agency, TorchSpec empowers researchers and engineers to train larger, more capable models, but it also raises questions about who controls these powerful tools and how they are deployed. The benefits accrue to those with access to cutting-edge hardware and infrastructure, potentially exacerbating disparities in AI development. Second-order consequences could include increased centralization of AI research in well-funded institutions or corporations, further marginalizing smaller players.
Bridge questions to consider: How might disaggregated training systems like TorchSpec be adapted to lower-resource environments? What are the ethical implications of prioritizing throughput over other model qualities, such as bias mitigation or energy efficiency? Would a more decentralized approach to speculative decoding training be feasible, and what would it require?
Counterstrike scan: If this narrative were part of a coordinated influence campaign, it might emphasize the inevitability of large-scale, high-performance AI systems while downplaying alternative approaches or critiques. However, the content does not exhibit signs of manipulation; it presents a technical solution with transparency about its goals and limitations. The focus remains on addressing a specific engineering challenge rather than pushing a broader agenda.
Sentinel — Human
Sentinel analysis incomplete — partial response from fallback model.