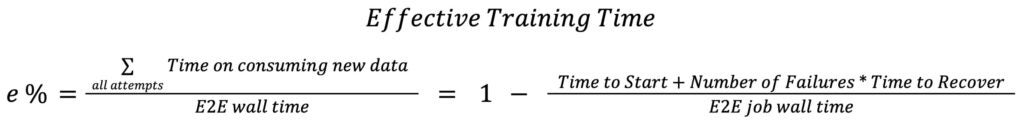
Motivation and Introduction
Across the industry, teams training and serving large AI models face aggressive ROI targets under tight compute capacity. As workloads scale, improving infrastructure effectiveness gets harder because end-to-end runtime increasingly includes overheads beyond “real training” (initialization, orchestration, checkpointing, retries, failures, and recovery).
Meta utilizes Ef...
The strongest version of this narrative is that Meta has systematically addressed inefficiencies in AI training by introducing a measurable metric (ETT%) and implementing targeted optimizations. The approach is data-driven, focusing on quantifiable bottlenecks like initialization, checkpointing, and recovery, which are often overlooked in favor of pure model performance metrics. By open-sourcing some of these improvements, Meta contributes to the broader AI community while retaining proprietary ...