Increasingly, Large-Language-Models (LLMs) are being trained for extremely long-context tasks, where token counts can exceed 100k+. At these token counts, out-of-memory (OOM) issues start to surface, even when scaling device counts using conventional training techniques such as ZeRO/FSDP. To circumvent these issues, sequence parallelism (SP): partitioning the input tokens across devices to enable long-context training with increasing GPU counts, is a commonly used parallel training technique.
However, implementing SP is notoriously difficult, requiring invasive code changes to existing libraries such as DeepSpeed or HuggingFace. These code changes often involve partitioning input token contexts (and intermediate activations), inserting communication collectives, and overlapping communication with computation, all of which must be done for both the forward and backwards pass. This results in researchers who want to experiment with long context capabilities spending significant effort on engineering the system’s stack to enable such capability, repeating this effort for different hardware vendors.
To avoid this complexity, we introduce AutoSP: a fully automated compiler-based solution that automatically converts easy-to-write training code to multi-GPU sequence parallel code that efficiently uses GPUs to train on longer input contexts while composing with existing parallel strategies (such as ZeRO). This avoids the cumbersome need for developers to repeatedly modify training pipelines for long-context training. Users can now simply import AutoSP and compile arbitrary models using the AutoSP backend, giving the power of long-context training to anyone. Moreover, by embedding this technology into the compiler, our approach is performance-portable: highly performant SP can be realised on diverse hardware.
We structure this post as follows: (1) AutoSP and how model scientists can use it to enable long-context training, (2) Key design decisions of AutoSP, (3) key AutoSP results, demonstrating its ease-of-use and impact, (4) some limitations and things AutoSP cannot do.
AutoSP Usage
A key design philosophy of AutoSP is simplicity in abstracting most of the complexity in programming multiple GPUs from users. To do this, we implement AutoSP within DeepCompile: a compiler ecosystem within DeepSpeed to programmatically enable diverse optimisations for deep neural network training. With this, any user who uses DeepSpeed can automatically enable Sequence Parallelism with almost zero hassle. We take a look at an example next.
We instantiate a deepspeed config.
Assume 8 GPUs with 2 DP ranks and 4 SP ranks.
config = {
"train_micro_batch_size_per_gpu": 1,
"train_batch_size": 2,
"steps_per_print": 1,
"optimiser": {
"type": "Adam",
"params": {
"lr": 1e-4
}
},
"zero_optimization": {
"stage": 1, # AutoSP interoperates with ZeRO 0/1.
},
Simply turn on deepcompile and set
the AutoSP pass to be triggered on.
"compile": {
"deepcompile": True,
"passes": ["autosp"]
},
"sequence_parallel_size": 4,
"gradient_clipping": 1.0,
}
Initialise deepspeed with model.
model, _, _ = deepspeed.initialize(config=config,model=model)
Compiles model and automatically applies AutoSP passes.
model.compile(compile_kwargs={"dynamic": True})
for idx, batch in enumerate(train_loader):
Custom function that we expose within:
deepspeed/compile/passes/sp_compile.
inputs, labels, positions, mask = prepare_auto_sp_inputs(batch)
loss = model(
input_ids=inputs,
labels=labels,
position_ids=positions,
attention_mask=mask
)
... # Backwards pass, optimiser step etc...
As seen in the example above, users take existing training code that runs on a single device and do the following: (1) use the prepare_autosp_input
utility function (exposed in DeepSpeed) for lightweight tagging of input tokens, attention masks and position ids for use in program analysis within AutoSP. (2) Adjust the DeepSpeed config to turn DeepCompile on, specifying the “passes” flag to “autosp”. The rest is handled through the AutoSP compiler passes, called when compiling the model, which automatically enable sequence-parallelism alongside other long-context training optimisations. AutoSP additionally automatically composes with ZeRO stage 1 out of the box, simply set the ZeRO-1 flag in DeepSpeed alongside the AutoSP flags to combine both strategies.
AutoSP Compiler Passes
Since AutoSP transforms user code to enable longer-context training, we briefly cover the key design points of AutoSP and code transformations, as well as its consequences to users for transparency.
Sequence Parallelism Code Transformations. AutoSP automatically converts single-GPU code to multi-GPU sequence parallel (SP) code. The specific SP strategy AutoSP converts code into is DeepSpeed-Ulysses. We specifically focus on DeepSpeed-Ulysses over other strategies (e.g. RingAttention) as its communication overhead stays constant with increasing GPU counts on NVLink network topologies or fat-tree networks. However, DeepSpeed-Ulysses only enables scaling the SP-size to the number of heads in a model (32 in 7-8B models).
Activation Checkpointing for longer-context training. AutoSP additionally applies a custom activation-checkpointing (AC) strategy curated for long-context modelling. AC releases intermediate activations of cheap-to-compute operators, recomputing them in the backwards pass as required to compute relevant gradients. PyTorch-2.0 introduces an automated max-flow min-cut based AC formulation, but we find this to be overly conservative for long-context modelling. We accordingly introduce a novel AC strategy targeted for long-context training: Sequence-aware AC (SAC), which exploits unique long-context FLOP dynamics. When triggered on (the default setting in AutoSP), this marginally reduces training throughput. However, without it, training on longer contexts is infeasible, so the user can selectively choose to turn this pass on only for configurations that OOM.
Evaluating AutoSP on Real Models
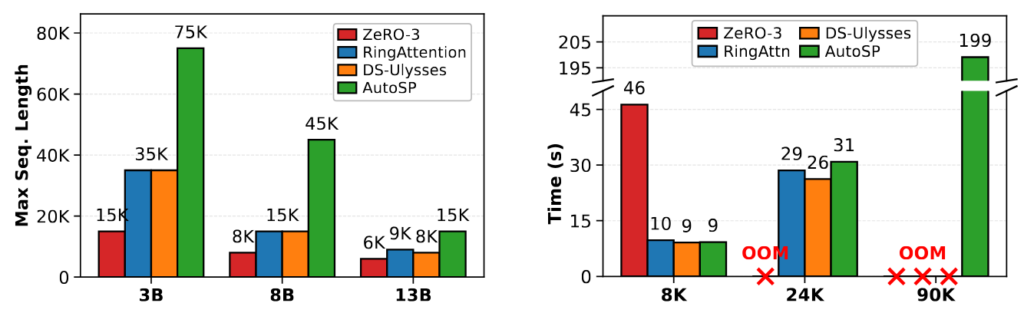
To demonstrate AutoSP’s viability, we evaluate its performance on models of varying sizes on NVIDIA GPUs to show that its ease of use comes at little to no cost to runtime performance. We benchmark different Llama 3.1 models on an 8 A100-80Gb SXM node. We use PyTorch 2.7 with CUDA 12.8, comparing AutoSP to torch-compiled hand-written baselines of: RingFlashAttention, DeepSpeed-Ulysses, and ZeRO-3. We summarise key results in the figure below:
Not only can AutoSP increase the maximum trainable sequence length given the same resources (left figure – higher is better), but also these benefits come at little cost to runtime performance (right figure – lower is better).
Limitations
There are two key limitations of AutoSP. First, we require that the user forcefully compile a transformer as a single compilable artifact. Occasionally, PyTorch users may compile many functions individually and stitch them together into one model. This is disallowed in AutoSP as we need to compile and see the entire model to correctly shard input sequences and propagate this information throughout the entire graph. Second, we disallow any graph breaks in compilable artifacts. This complicates analysis and propagation of information, and we leave extending AutoSP to be graph-break resilient to future research.
Conclusion
AutoSP enables users to easily extend arbitrary transformer training code to enable Sequence Parallelism, with a custom AC strategy for enhanced long-context training. Integration with DeepSpeed allows users to easily use existing DeepSpeed training code to train on longer contexts by simply changing a config file. We have prepared end-to-end examples for users to play around with on real model workloads (e.g. Llama 3.1 8B) here. Give it a try to see how easy long context training has become.
Facts Only
AutoSP is a compiler-based solution for long-context training of LLMs.
It uses DeepSpeed-Ulysses and a custom activation-checkpointing strategy.
Implemented within the DeepCompile ecosystem of DeepSpeed.
Users change configuration to enable Sequence Parallelism with AutoSP passes.
Works with existing parallel strategies like ZeRO.
Executive Summary
AutoSP is an automated compiler-based solution designed to enable long-context training for large language models (LLMs) without the need for invasive code changes. It works by transforming single-GPU code into multi-GPU sequence parallel (SP) code using DeepSpeed-Ulysses and applying a custom activation-checkpointing strategy. This allows users to train on longer input contexts with ease, while also composing with existing parallel strategies like ZeRO. AutoSP is integrated with DeepSpeed, making it easy for users to implement SP by simply changing a configuration file.
The system addresses the complexities of implementing SP by automating the partitioning of input token contexts and intermediate activations, inserting communication collectives, and overlapping communication with computation, both in the forward and backward pass. This simplifies the process for researchers who want to experiment with long-context capabilities without having to repeatedly modify their training pipelines for different hardware vendors.