Authors: Duna Zhan | Machine Learning Engineer II; Qifei Shen | Senior Staff Machine Learning Engineer; Matt Meng | Staff Machine Learning Engineer; Jiacheng Li | Machine Learning Engineer II; Hongda Shen | Staff Machine Learning Engineer
Introduction
Pinterest ads show up across multiple product surfaces, such as the Home Feed, Search, and Related Pins. Each surface has different user intent and different feature availability, but they all rely on the same core capability: predicting how likely a user is to engage with an ad.
Before this project, the ads engagement stack relied on three independent production models, one per surface. Although the models were initially derived from a similar design, they diverged over time in several core components, including user sequence modeling, feature crossing modules, feature representations, and training configurations. This fragmentation led to persistent operational and modeling inefficiencies:
- Low iteration velocity: Platform-wide improvements required duplicating work across multiple codepaths, and hyperparameters tuned for one surface often could not transfer to others.
- Redundant training cost: Similar ideas had to be validated separately on each model, substantially increasing experimentation and training overhead.
- High maintenance burden: Operating, debugging, and evolving three materially different systems was significantly more complex than maintaining a unified stack.
These challenges motivated the development of a unified engagement framework to gradually consolidate surface-specific models while retaining the flexibility needed for each surface.
In this post, we present our approach to unifying two previously separate engagement models into a single architecture with surface-specific calibration and lightweight surface-specialized components. We also describe several efficiency optimizations such as projection layers and request-level broadcasting, which reduce infrastructure costs. Overall, the unified model not only resolves the iteration, cost, and maintenance issues described above, but also strengthens representation learning by combining complementary features and modeling choices across surfaces, leading to significant online metric improvements.
Methodology: modeling & architecture evolution
Unification strategy and guiding principles
We treated model unification as a major architectural change and followed three principles to avoid common failure modes:
- Start simple: Establish a pragmatic baseline by merging the strongest existing components across surfaces.
- Iterate incrementally: Introduce surface-aware modeling (e.g., multi-task heads, surface-specific exports) only after the baseline demonstrates clear value.
- Maintain operational safety: Design for safe rollout, monitoring, and fast rollback at every step.
We also set explicit milestones based on serving constraints. Since the cost of Related Pins (RP), Home Feed (HF), and Search (SR) differ substantially, we first unified Home Feed and Search (similar CUDA throughput characteristics) and expanded to Related Pins only after throughput and efficiency work stabilized.
Baseline unified model
As a first step, we built a baseline unified model by:
- Unioning features across the three surface models,
- Merging existing modules into a single architecture, and
- Combining training datasets across surfaces.
This baseline delivered promising offline improvements, but it also materially increased training and serving cost. As a result, additional iterations were required before the model was production-ready.
Architecture refinement for Home Feed and Search
Because RP had a substantially higher cost profile, we focused next on unifying HF and SR. We incorporated key architectural elements from each surface such as MMoE [1] and long user sequences [2]. When applied in isolation (e.g., MMoE on HF alone, or long sequence Transformers on SR alone), these changes did not produce consistent gains, or the gain and cost trade-off was not favorable. However, when we integrated these components into a single unified model and expanded training to leverage combined HF+SR features and multi-surface training data, we observed stronger improvements with a more reasonable cost profile.
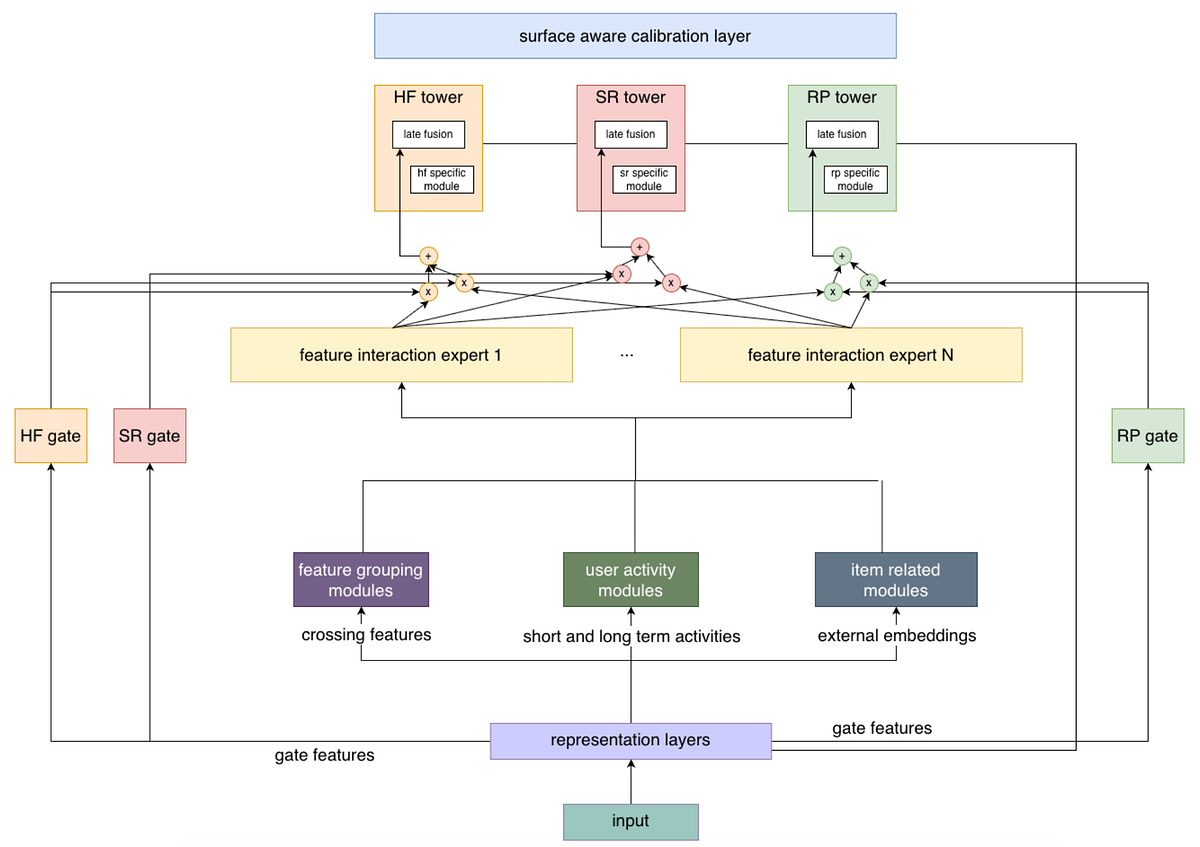
The diagram below shows the final target architecture: a single unified model that serves three surfaces, while still supporting the development of surface-specific modules (for example, surface-specific tower trees and late fusion with surface-specific modules within those tower trees). During serving, each surface-specific tower tree and its associated modules will handle only that surface’s traffic, avoiding unnecessary compute cost from modules that don’t benefit other surfaces. As a first step, the unified model currently includes only the HF and SR tower trees.
Surface-specific calibration
Since the unified model serves both HF and SR traffic, calibration is critical for CTR prediction. We found that a single global calibration layer could be suboptimal because it implicitly mixes traffic distributions across surfaces.
To address this, we introduced a view type specific calibration layer, which calibrates HF and SR traffic separately. Online experiments showed this approach improved performance compared to the original shared calibration.
Multi-task learning and surface-specific exports
Using a single shared architecture for HF and SR CTR prediction limited flexibility and made it harder to iterate on surface-specific features and modules. To restore extensibility, we introduced a multi-task learning design within the unified model and enabled surface-specific checkpoint exports. We exported separate surface checkpoints so each surface could adopt the most appropriate architecture while still benefiting from shared representation learning.
This enabled more flexible, surface-specific CTR prediction and established a foundation for continued surface-specific iteration.
Model and serving efficiency improvements
Infrastructure cost is mainly driven by traffic and per-request compute, so unifying models does not automatically reduce infra spend. In our case, early unified versions actually increased latency because merging feature maps and modules made the model larger. To address this issue, we paired it with targeted efficiency work.
We simplified the expensive compute paths by using DCNv2 to project the Transformer outputs into a smaller representation before downstream crossing and tower tree layers, which reduced serving latency while preserving signal. We also enabled fused kernel embedding to improve the inference latency and TF32 to speed up training speed.
On the serving side, we reduced redundant embedding table look up work with request-level broadcasting. Instead of repeating heavy user embedding lookups for every candidate/request in a batch, we fetch embeddings once per unique user and then broadcast them back to the original request layout, keeping model inputs and outputs unchanged. The main trade-off is an upper bound on the number of unique users per batch; if exceeded, the request can fail, so we used the tested unique user number to keep the system reliable.
Evaluation
In offline experiments, we observed improvements across HF and SR, and validated the performance gains by online experiments. As shown in the table below, we observed significant improvements on both online and offline metrics [3].
Conclusion
Unifying ads engagement modeling isn’t simply a matter of replacing three separate models with one. The real objective is to build a single, cohesive framework that can share learning wherever it reliably generalizes across surfaces, while still making room for surface-specific features and behavioral nuances when they genuinely matter. At the same time, the framework has to remain efficient enough to serve at scale. Ultimately, by consolidating the core approach and eliminating repeated effort, we reduce duplicated work and put ourselves in a position to ship improvements faster and more consistently.
In the next milestone, we plan to unify the RP surface for the engagement model to create a more consistent experience and consolidate the model. The primary challenge will be model efficiency, so we will integrate additional efficiency improvements to meet our performance targets and achieve this goal.
Acknowledgements
This work represents a result of collaboration of the ads ranking team members and across multiple teams at Pinterest.
Engineering Teams:
- Ads Ranking: Yulin Lei, Randy Carlson, Erika Sun (former), Zhixuan Shao, Kungang Li
- Ads ML Infra: Sihan Wang, Yuying Chen, Anton Kustov, Xinyi Zhang
- Leadership: Jamieson Kerns, Ling Leng (former), Jinfeng Zhuang (former), Dongtao Liu (former), Liangzhe Chen, Degao Peng, Zhifang Liu, Caijie Zhang, Shu Zhang (former), Haoyang Li (former), Xiaofang Chen (former), Yang Tang
References
[1] Li, Jiacheng, et al. “Multi-gate-Mixture-of-Experts (MMoE) model architecture and knowledge distillation in Ads Engagement modeling development”. Pinterest Engineering Blog.
[2] Lei, Yulin, et al. “User Action Sequence Modeling for Pinterest Ads Engagement Modeling”. Pinterest Engineering Blog.
[3] Pinterest Internal Data, US, 2025.
Facts Only
Authors: Duna Zhan, Qifei Shen, Matt Meng, Jiacheng Li, Hongda Shen
Project: Unifying ads engagement modeling across surfaces on Pinterest (Home Feed, Search, and Related Pins)
Goals: Create a single, cohesive framework for efficient learning while catering to surface-specific features
Challenges addressed: Low iteration velocity, redundant training cost, high maintenance burden, inconsistent performance
Principles followed: Start simple, iterate incrementally, maintain operational safety
Approach: Unifying features, merging modules, combining training datasets, introducing multi-task learning and surface-specific exports
Efficiency optimizations: Projection layers, request-level broadcasting, DCNv2, fused kernel embedding, TF32
Results: Significant improvements in online metrics after unifying Home Feed and Search models; plans to further expand to Related Pins
Executive Summary
In this article, the authors discuss a project to unify Pinterest's ads engagement modeling across different surfaces such as Home Feed, Search, and Related Pins. The goal is to create a single, efficient framework that can share learning effectively while still catering to surface-specific features and behavioral nuances.
The project addresses several challenges caused by the fragmentation of three independent production models, including low iteration velocity, redundant training cost, high maintenance burden, and inconsistent performance. To achieve this, they follow principles such as starting simple, iterating incrementally, and maintaining operational safety. The approach involves unifying features, merging modules, combining training datasets, and introducing multi-task learning and surface-specific exports.
Efficiency optimizations like projection layers, request-level broadcasting, DCNv2, fused kernel embedding, and TF32 were also integrated to reduce infrastructure costs. The results show significant improvements in online metrics after unifying Home Feed and Search models, with plans to further expand to Related Pins.
Full Take
Analysis:
* Steelman — The article presents a clear goal of improving the efficiency and consistency of Pinterest's ads engagement modeling across multiple surfaces. It describes an approach that involves unifying features, merging modules, combining training datasets, introducing multi-task learning, and surface-specific exports while also employing efficiency optimizations to reduce infrastructure costs.
* Pattern scan — None detected in this article.
* Root cause — The underlying motivation seems to be a desire for improved operational efficiency, cost reduction, and better model performance across different surfaces of Pinterest's ads platform.
* Implications — The unified model could lead to faster iterations, reduced training costs, lower maintenance burden, and improved online metrics, making the ads platform more effective and potentially increasing revenue for Pinterest.
* Bridge questions — How will the expansion to Related Pins impact performance and efficiency? What other improvements can be made to further optimize the unified model? How might this approach influence similar platforms in the industry?
* Counterstrike scan — There are no indications that this project is part of a coordinated influence campaign. The article presents a straightforward discussion of a technical project aimed at improving efficiency and performance within Pinterest's ads platform.