At Square, we manage large amounts of information for our merchants. This includes the data surrounding what a merchant sells — their…
At Square, we manage large amounts of information for our merchants. This includes the data surrounding what a merchant sells — their products, prices, taxes, and the configurations associated with those entities. We refer to this dataset as a merchant’s catalog.
Managing this data can be challenging. Merchants’ catalogs can be quite large. They must be synced with mobile devices which may be offline for extended periods of time, allowing the two versions of the catalog to diverge. Catalogs need a sophisticated query interface to support a responsive web UI, but they also need to support large bulk operations via API, including re-writing the entire data set. Additionally, the data needs structure to allow it to display and function properly across a variety of services and mobile clients, but it also needs enough flexibility to allow rapid development of new features, and to enable merchants and third parties to create custom data specific to their business or integration.
We recently re-architected the system that we use for storing catalog data, and are writing this article to share some of our learnings. We needed a number of the features offered by traditional databases. For example, we needed to write data without impacting reads until the entire operation is complete (even across multiple API calls). We wanted to be able to page through data consistently even if other clients are writing to the catalog. These features needed to be per-user, so that activity by one user would not impact another. At the same time, we needed much more structure than a traditional database would provide, while still allowing new elements to be added without the need for a schema change, re-deploy or migration.
We accomplished this by using an entity-attribute-value data model, where entities have types which may be system defined and attributes that follow specific attribute definitions, which may be system or user defined. By using an append-only data model, we were able to achieve the transactionality properties that we needed without relying on transactions in the underlying sharded MySql database, which we chose as a storage infrastructure due to strong institutional support.
Merchant datastore design
Structured, but Flexible
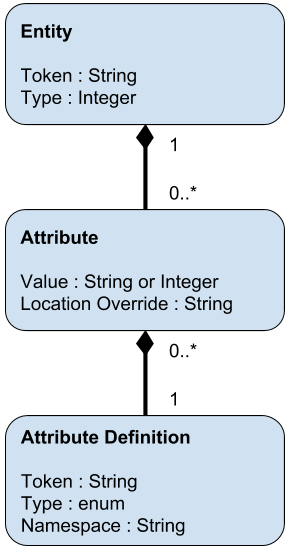
We needed an object model that was structured enough to allow clients to handle data in predictable formats, but which had enough flexibility to allow clients, integrators, and even end-users to extend the data model for their own use cases. We settled on an entity-attribute-value store with a few characteristic features. The model could be represented as follows:
Each object has a unique token and a predefined type. It has a set of attributes, which must use a predefined definition. An attribute definition specifies the type of the attribute and is used by clients to validate and interpret the attribute data. It is namespaced in a way that identifies its owner. Definitions and (eventually) types can be created via API. The same definition can appear in multiple attributes, allowing for sets of values to be represented. Attributes can reference other objects by their tokens, allowing for more complex data to be represented through related objects. We will discuss location overrides below.
Features
One of the key values of this model is that it allows clients to operate with structured data which they understand, while allowing indefinite extensibility. New object types can be added with ease, including allowing clients to create new object types via API. Likewise, new attribute definitions can be added via API. Having attributes definitions namespaced (according to the Java package convention) makes it easy to distinguish the owner of the attribute definition, and can be used to prevent non-owners from overwriting definitions. For efficiency and consistency, standard types and definitions are shared across all users, while user created types are only visible to the individual user.
One domain-specific behavior that we wanted to support in a first-class fashion is the concept of the location. Within our user model, a merchant may have multiple physical or virtual locations where they conduct business. Some clients are location-aware, which means that they only need to have the data particular to a specific location, while others are merchant-aware, meaning that they need visibility into all locations. Values on the same object can also vary by location, for example, the same product might have different prices in different locations. We support this by giving each attribute a location value, which is global by default. When a location-aware client requests data, we send only the global attributes and attributes for the client’s location, allowing the client to operate on a smaller and simpler data set. Merchant aware clients must handle the complexity of values which may have different values at different locations. Objects can also be entirely removed from individual locations through a special “enabled” attribute, which can toggle availability.
Synchronizable Constraints
One of the more interesting features of our datastore is its use of synchronizable constraints. Having data with a constant structure is key to building clients that can understand and use it properly. Constraints ensure that clients can expect data to have a given format, and protects them from other clients creating or modifying data in an unexpected way.
Instead of relying on database level constraints which require schema changes to alter, we wanted constraints to be easy to introduce while maintaining consistent behavior across the core datastore and mobile clients. For this reason, we modeled constraints as catalog objects themselves, which allows them to be created via API and synced with mobile clients. In this way, a client creating a new object type or attribute definition could create new constraints ensuring that it has the specified structure.
Constraints are built on special global attributes that trigger software validations that must be built on mobile clients as well as the core service. They provide for validations ranging from requiring attributes, to specifying valid integer ranges, to regular expression matches, to requiring that references not be broken, to cascading deletions if a referenced object is deleted. Put together, they create a large palette of options that enables object structure to be tightly constrained.
Allowing these constraints to be synced to clients enables clients to enforce constraints as soon as a violation takes place, rather than waiting for the invalid object to be sent to the server to receive an error message. This speeds debugging, and, in the unfortunate case where code that creates invalid objects is released, limits the potential impact of that bug on customers.
Rollback and History
At the core of the merchant catalog is an append-only data model. When a request is received to delete or modify an object, entities are marked as having been deleted by the request in question, and are not returned in future requests. This is made relatively efficient by handling modifications by creating deletions at the attribute level. Thus, a request that modifies a single attribute only creates one new attribute entry, rather than an entire new object.
This data model allows a number of useful features. For example, a response to a query to page through the merchants data includes a paging token that encodes the current catalog version. Requests for additional pages with the same token will ignore deletions and creations that took place after that version, allowing for consistent paging.
This tooling is easily extended to allow a historic lookback of a catalog as of a specific request. Supplying a specific catalog version (which is incremented with each write request) makes it possible to view the entire catalog as it existed at that point in time. It also makes it possible to query the set of changes after that point in time, which makes it trivial to revert those changes, and restore a catalog to a previous version. Because rollbacks are themselves append-only changes to the datastore, they can be reverted in turn.
This same functionality makes it possible to expose user level transactions. As an optional parameter, a put request can request to open a transaction. If a transaction is opened, the merchant’s catalog is locked with a token that is returned to the client. Other attempts to write the catalog are blocked while the catalog is locked, and requests to read receive that catalog as of the lock version without any incremental changes. Additional writes with the token update the lock version, allowing changes to continue inside the transaction for as long as necessary without impacting other users. When the transaction is completed, the lock is removed, and all operations access the catalog with the modifications from the transaction.
If a request is received to roll back the transaction, all changes made after the lock version are deleted, and there are no side effects from the aborted transaction. Likewise, if a client that opens a transaction does not make any write calls within a timeout, the transaction is automatically rolled back. This allows long running operations, such as the import of new catalog data, to execute atomically, and allows clients to always read the catalog as of a clean version.
Finally, this model provides auditability. Because every write is tagged with information about the caller, it becomes possible not only to view the catalog as of a certain period, but to attribute specific changes to specific callers. This is a great help in debugging clients that make unexpected changes to a catalog, and also makes it possible for users to know the individual responsible for specific modifications.
Conclusion
While the merchant catalog datastore was designed for our specific needs, it has a number of behaviors which may be of use for other applications. Specifically, using an append-only datastore enables a number of useful behaviors which greatly increase the flexibility of the platform. APIs for creating attribute definitions and syncable constraints allow data to be structured and validated while enabling multiple parties to independently iterate on their own parts of the model. We hope that our learnings may be useful to others facing similar problems.
Facts Only
Square manages large datasets for merchants, including product catalogs with prices, taxes, and configurations.
The company re-architected its datastore system to handle challenges like offline mobile syncing and large dataset sizes.
The new system uses an entity-attribute-value data model with predefined types and attributes.
Attribute definitions are namespaced to identify owners and prevent conflicts.
The system supports location-specific data overrides, allowing different values (e.g., prices) per merchant location.
Synchronizable constraints are modeled as catalog objects, enabling validation across mobile clients and the core service.
The datastore uses an append-only model, marking deletions rather than removing data.
Paging tokens encode catalog versions, ensuring consistent data retrieval during queries.
Rollback functionality allows reverting to previous catalog versions by referencing specific write requests.
Transactions can be opened via API, locking the catalog to prevent concurrent modifications.
Auditability is achieved by tagging writes with caller information, enabling change attribution.
The system is built on a sharded MySQL database due to institutional support.
New object types and attribute definitions can be created via API without schema changes.
Executive Summary
Square, a financial services company, manages extensive merchant data, including product catalogs with prices, taxes, and configurations. The company recently re-architected its datastore system to address challenges like large dataset sizes, offline mobile syncing, and the need for both structured and flexible data models. The new system uses an entity-attribute-value model with append-only storage, allowing for transactional consistency without traditional database transactions. Key features include location-specific data overrides, synchronizable constraints for validation, and rollback capabilities for historical data recovery. The design supports both merchant-aware and location-aware clients, enabling efficient data handling across multiple business locations. The system also provides auditability by tracking changes to specific callers, aiding in debugging and accountability. Square's approach balances structure with flexibility, allowing rapid feature development while maintaining data integrity across mobile and web platforms.
The solution leverages MySQL for storage but avoids schema changes by modeling constraints as catalog objects, syncable with mobile clients. This ensures consistent validation across all platforms and reduces latency in error detection. The append-only model enables features like consistent paging, transactional locks for bulk operations, and historical snapshots, which are critical for merchant operations. The system is designed to handle large-scale bulk operations, such as full catalog rewrites, without disrupting read operations. By namespacing attribute definitions, Square prevents conflicts between system-defined and user-created data structures, fostering a collaborative yet controlled environment for merchants and third-party integrators.
Full Take
Square’s datastore redesign offers a compelling case study in balancing structure and flexibility in large-scale systems. The strongest version of this narrative highlights its innovative use of an append-only, entity-attribute-value model to achieve transactional consistency without traditional database locks, a significant engineering feat. The system’s ability to sync constraints with mobile clients—enabling real-time validation—reduces latency in error detection and improves user experience. Location-specific overrides and rollback capabilities address real-world merchant needs, such as multi-location pricing and data recovery. The design also fosters collaboration by allowing third parties to extend the data model without schema changes, a rare blend of control and openness.
However, the narrative leans heavily on technical sophistication as a justification, which could obscure trade-offs. For instance, the append-only model, while powerful, may introduce storage inefficiencies over time. The reliance on MySQL, despite its institutional support, raises questions about scalability limits as merchant datasets grow. The system’s complexity—with constraints, transactions, and location overrides—could also create maintenance burdens or onboarding challenges for smaller merchants. The emphasis on flexibility might inadvertently enable data fragmentation if not governed carefully.
Root cause: The paradigm here is "controlled decentralization"—giving merchants and integrators autonomy while maintaining systemic integrity. This echoes broader trends in API-driven ecosystems, where platforms seek to balance innovation with stability. The unstated assumption is that merchants will use this flexibility responsibly, but without guardrails, it could lead to unintended data silos or validation gaps.
Implications: For human agency, this system empowers merchants to customize their data models, but the learning curve may disproportionately benefit larger businesses with technical resources. The auditability features enhance accountability, though they also centralize control over data narratives. Second-order consequences could include increased reliance on Square’s infrastructure, locking merchants into its ecosystem.
Bridge questions: How might smaller merchants without technical expertise navigate this system’s complexity? What safeguards prevent attribute definition conflicts in a multi-integrator environment? Would a hybrid model—combining strict schemas for core data with flexible extensions—better serve both stability and innovation?
Counterstrike scan: If this were an influence campaign, the playbook would emphasize technical superiority to preempt criticism ("only we can solve this complexity"). The actual content aligns with this by framing the solution as uniquely capable, but it stops short of dismissing alternatives. No overt manipulation detected; the focus remains on engineering trade-offs.
Patterns detected: none
Sentinel — Human
The article exhibits strong indicators of human authorship, including domain-specific expertise, idiosyncratic phrasing, and technical nuance, with no significant stylometric or coherence red flags suggestive of AI generation.